- Annexes
- Liste des annexes
- Annexe 1
- Annexe 2
- Annexe 3
- Annexe 4
- Annexe 5
- Annexe 6
- Annexe 7
- Annexe 8
- Annexe 9
- Annexe 10
- Annexe 11
- Annexe 12
- Annexe 13
- Annexe 14
- Annexe 15
- Annexe 16
- Annexe 17
- Annexe 18
- Annexe 19
- Annexe 20
- Annexe 21
- Annexe 22
- Annexe 23
- Annexe 24
- Annexe 25
- Annexe 26
- Annexe 27
- Annexe 28
- Annexe 29
- Annexe 30
- Annexe 31
- Annexe 32
- Annexe 33
- Annexe 34
- Annexe 35
- Annexe 36
- Annexe 37
- Annexe 38
- Annexe 39
- Annexe 40
- Annexe 41
- Annexe 42
- Annexe 43
- Annexe 44
- Annexe 45
- http://leblanc.jeanmarc.free.fr/
- Blog de Textopol
Représentation rectangulaire des distances
3.1 Représentation des distances du Chi2, sur le Vocabulaire (Méthode Jacquart)
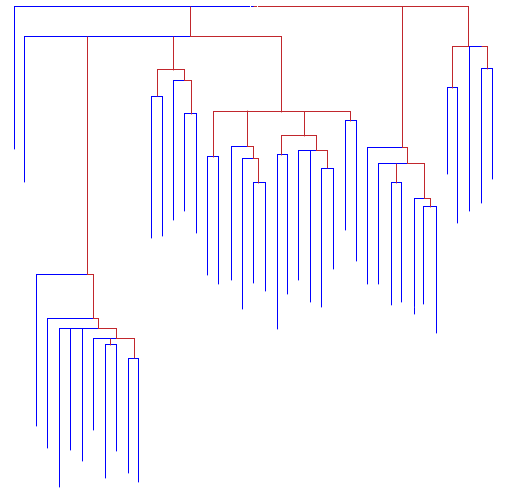 Cette représentation repose sur une classification ascendante hiérarchique[1] prenant en entrée les données produites par les différents calculs de distance lexicale (sur V) ou intertextuelle (sur N). Les éléments les plus proches sont groupés deux à deux puis s’agrègent progressivement en blocs plus larges, jusqu’à épuisement des itérations. Ces dendrogrammes apportent un complément à l’analyse factorielle mais aussi aux représentations radiales en ce sens que les noeuds indiquent clairement les imbrications et les étapes de regroupement des textes. On parle de classification hiérarchique en ce sens que chaque classe d’une partition est incluse dans la suivante.
Cette représentation repose sur une classification ascendante hiérarchique[1] prenant en entrée les données produites par les différents calculs de distance lexicale (sur V) ou intertextuelle (sur N). Les éléments les plus proches sont groupés deux à deux puis s’agrègent progressivement en blocs plus larges, jusqu’à épuisement des itérations. Ces dendrogrammes apportent un complément à l’analyse factorielle mais aussi aux représentations radiales en ce sens que les noeuds indiquent clairement les imbrications et les étapes de regroupement des textes. On parle de classification hiérarchique en ce sens que chaque classe d’une partition est incluse dans la suivante.
3.2 Distance sur N (Méthode Labbé)
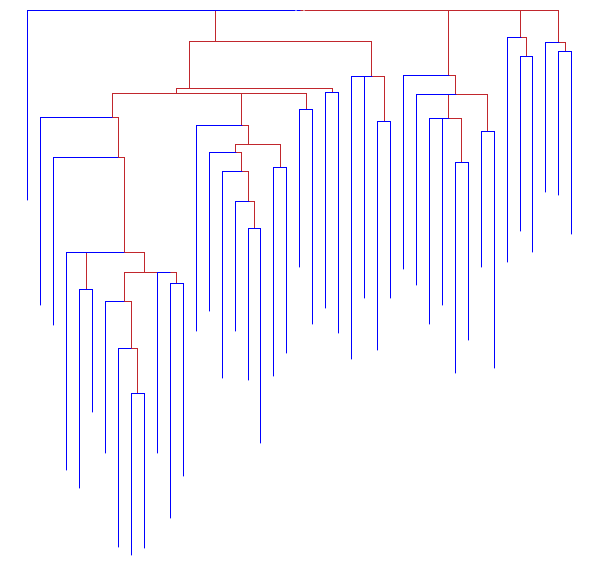
[1] : Pour de plus amples approfondissement sur ces méthodes on consultera (Bouroche, Saporta, 1980), (Lebart, Salem, 1994, p.111) ; (Habert, Nazarenko, Salem, 1997 p.198).