
Dans cette configuration, il s’agit de traiter un dossier contenant plusieurs fichiers texte.
Dans ce cas il n’est pas nécessaire d’introduire de balisage, la partition sera créée en fonction du nom des fichiers.
Procédure: placer dans un dossier les différentes parties du corpus au format texte brut. (Un fichier par partie).
Exemple du corpus textes_genres
Décompresser l’archive et copier le dossier textes_genres dans le répertoire de TextObserver
Le dossier textes_ genres contient 5 fichiers txt
Lancer TextObserver (voir procédure)
Importer le corpus au moyen de la procédure suivante :
Menu Fichier > Importer> Répertoire de corpus> Format TXT…
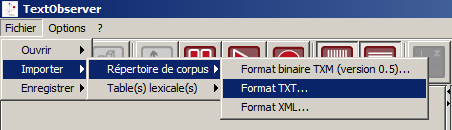
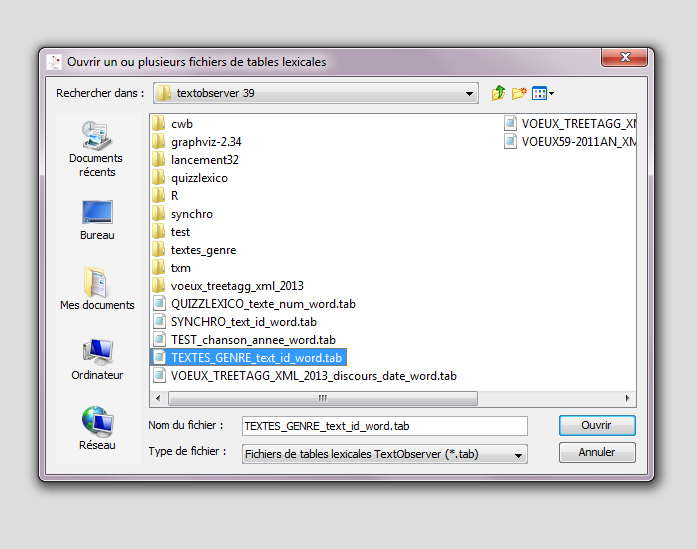
Choisir le dossier contenant les fichiers texte
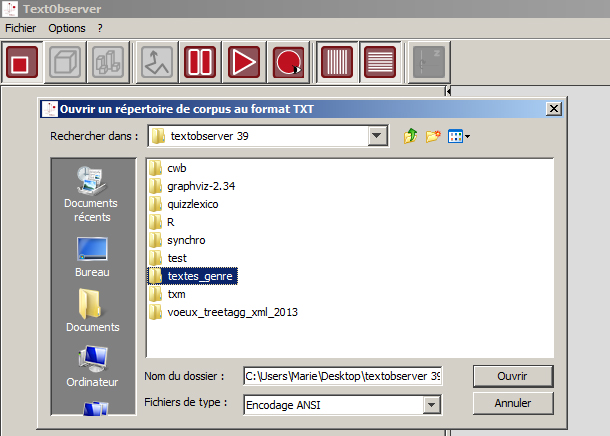
Cliquer sur « Ouvrir » après avoir choisi le bon encodage
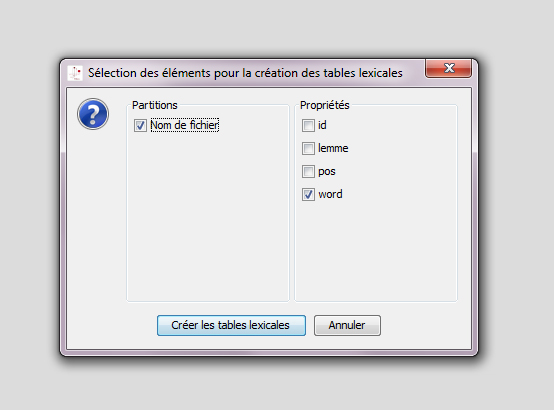
Choisir les propriétés lorsque le panneau ci-dessus apparaît.
Cliquer sur « Créer les tables lexicales ».
A l’issue de la procédure le message suivant s’affiche.
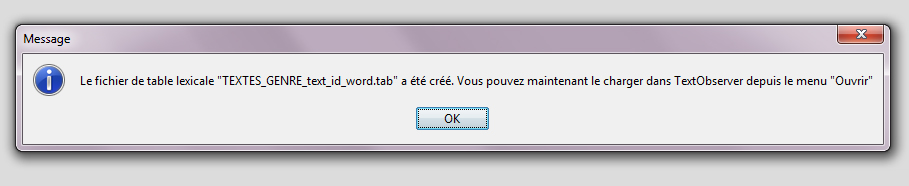
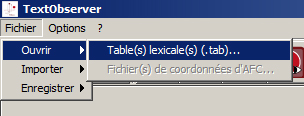
Après validation, ouvrir la table ainsi créée. (Fichier > Ouvrir > Table(s) Lexicale(s)…)
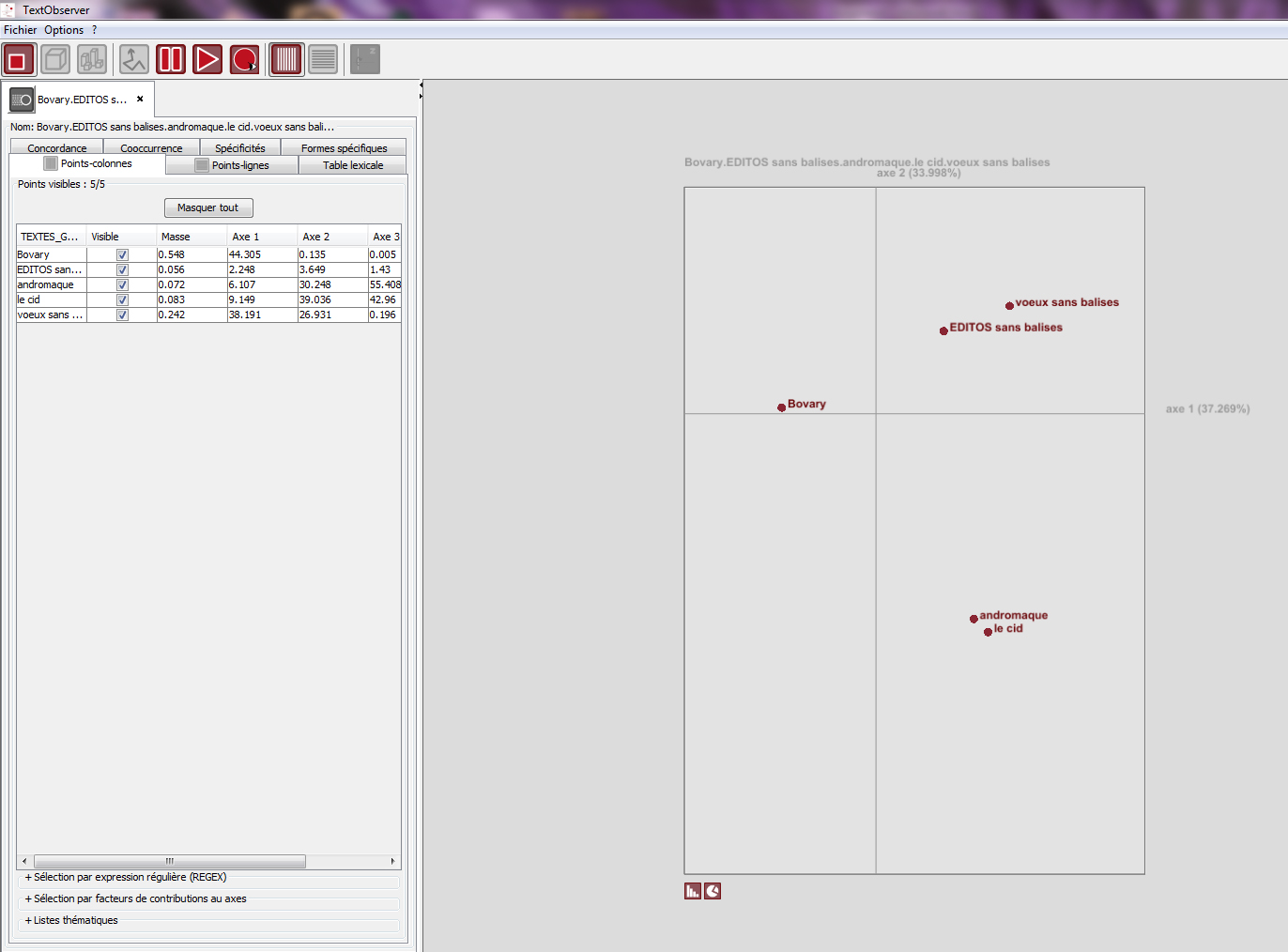
Le corpus est prêt, l’exploration peut commencer…
 You can load several text files once by loading a directory.
You can load several text files once by loading a directory.
You don’t need to tag it. The parting will be done using the text files (one text eq. one partition).
In order to do that, place in a directory all the text files forming your corpus in plain text format (one file for each part).
An exemple : textes_genres corpus
Down load : >> http://textopol2.u-pec.fr/wp-content/uploads/2013/11/textes_genre.zip
Unzip the file and copy-paste the directory in the root directory of TextObserver
There is 5 text files in textes_ genres directory