TextObserver permet d’importer des corpus sous forme de fichiers texte partitionnés (un fichier par partition, le tout dans un dossier), des corpus balisés en xml (pour faciliter la tâche nous avons développé un utilitaire nommé TextEncoder. Celui-ci permet de transformer facilement un corpus étiqueté sous Cordial, Treetagger ou tout autre outil générant des données tabulées en fichier xml).
>> voir rubrique : Balisage xml sur la forme graphique
1. Import du fichier xml
Ce fichier dont l’extension doit impérativement être xml, doit être placé dans un dossier en racine de TextObserver.
Lancer TextObserver puis :
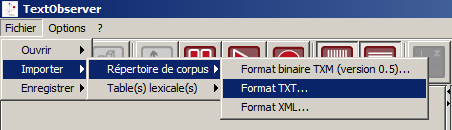
Menu Fichier>Importer>Répertoire de corpus>Format xml…
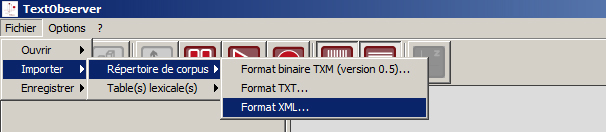
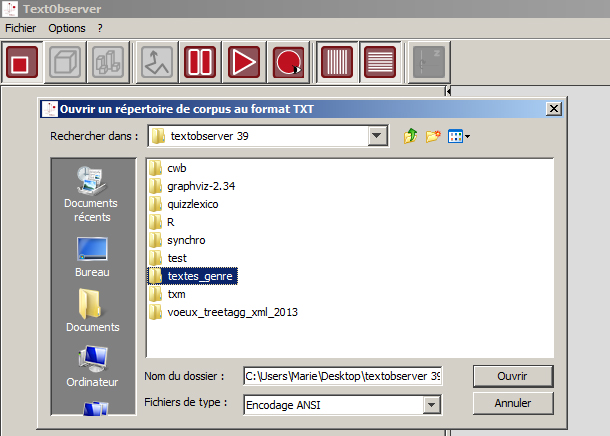
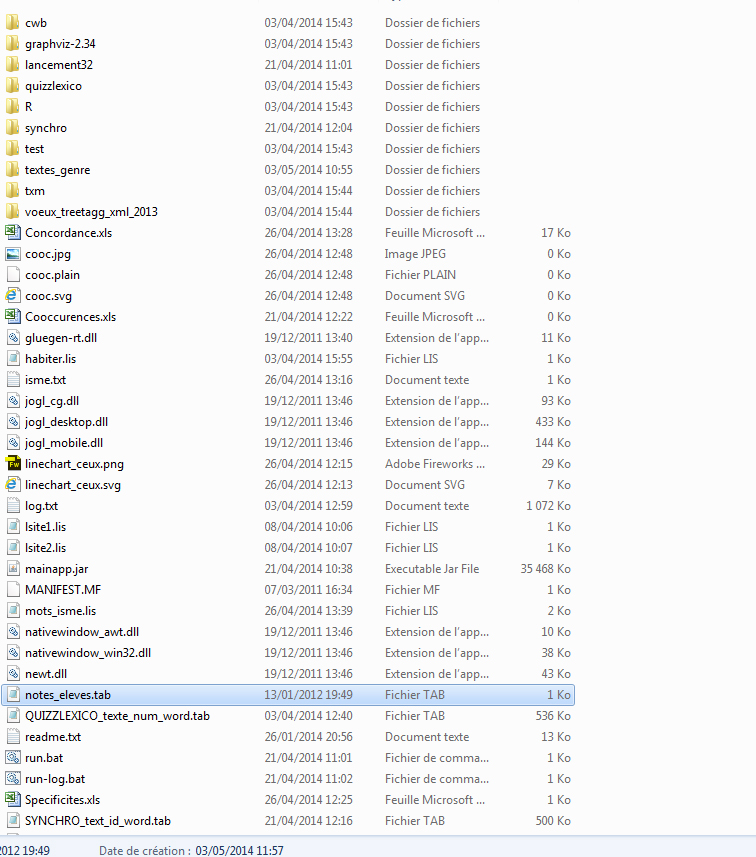
Choisir le dossier contenant le fichier xml à importer et, si nécessaire, modifier le type d’encodage (*)
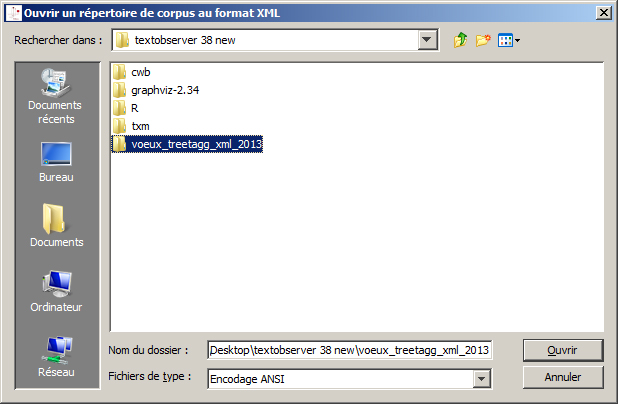
2. Création des tables lexicales
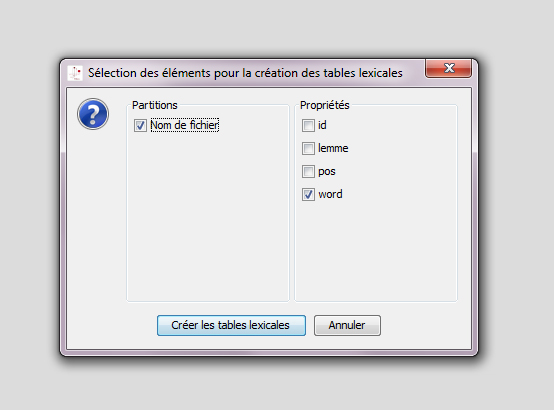
Une fois le calcul fait, TextObserver affiche la fenêtre ci-dessous proposant de choisir les partitions et les propriétés permettant de créer différentes tables lexicales. Ainsi, TextObserver, dans l’exemple ci-dessous, créera une table lexicale discours_date sur la propriété word et une table discours_loc sur la même propriété. Sur un corpus catégorisé, il n’est pas nécessaire de cocher les cases pos ou lemme pour effectuer des recherches portant sur toutes les dimensions du corpus. En revanche si l’on souhaite créer une analyse factorielle portant sur les pos ou les lemmes il faudra cocher ces options.
Remarque : Les propriétés dépendent de l’encodage choisi pour construire le fichier xml et ne sont pas limitées aux trois de cet exemple (>> voir rubrique création d’un corpus xml)
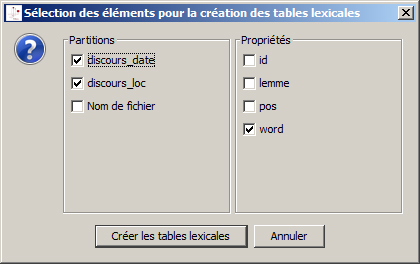
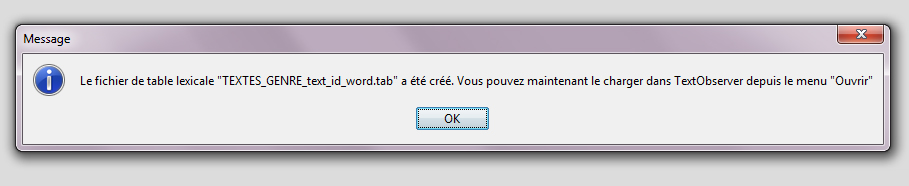
Valider « Créer les tables lexicales » lance leur fabrication.

3. Chargement des tables lexicales
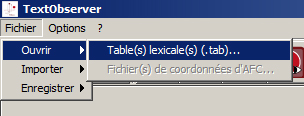
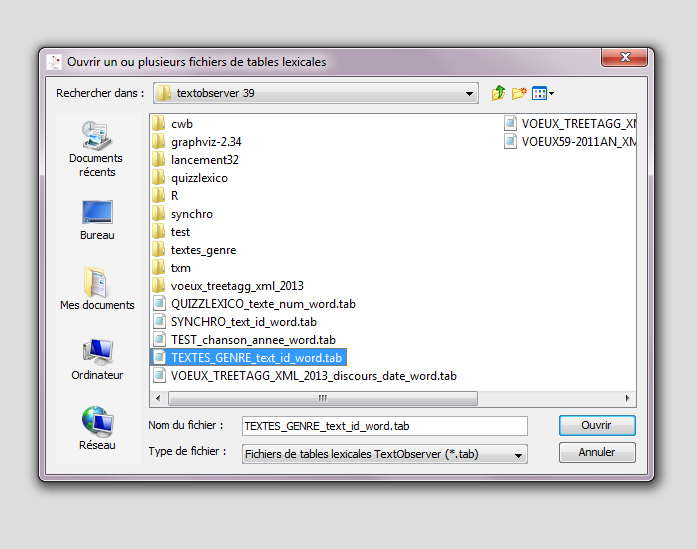
Menu Fichier>Ouvrir>Table(s) lexicale(s) (.tab)…

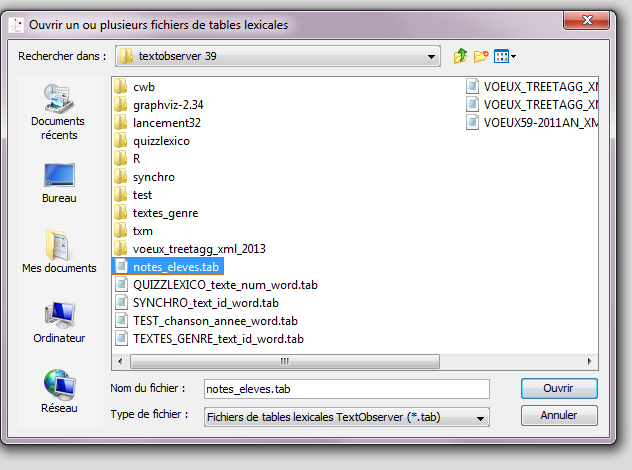
Choisir la table que vous désirez charger…
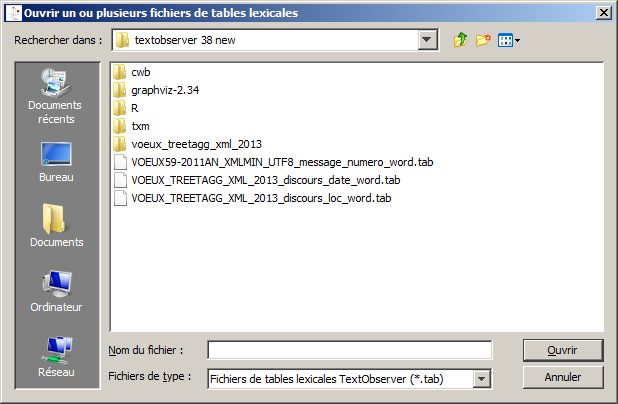
* : Le type d’encodage d’un fichier peut facilement être vérifié ou modifié grâce au logiciel gratuit et libre Notepad++ (voir manuel Notepad++ sur Textopol) Il permet également de transformer rapidement un fichier balisé pour Lexico3 en fichier xml (idem)
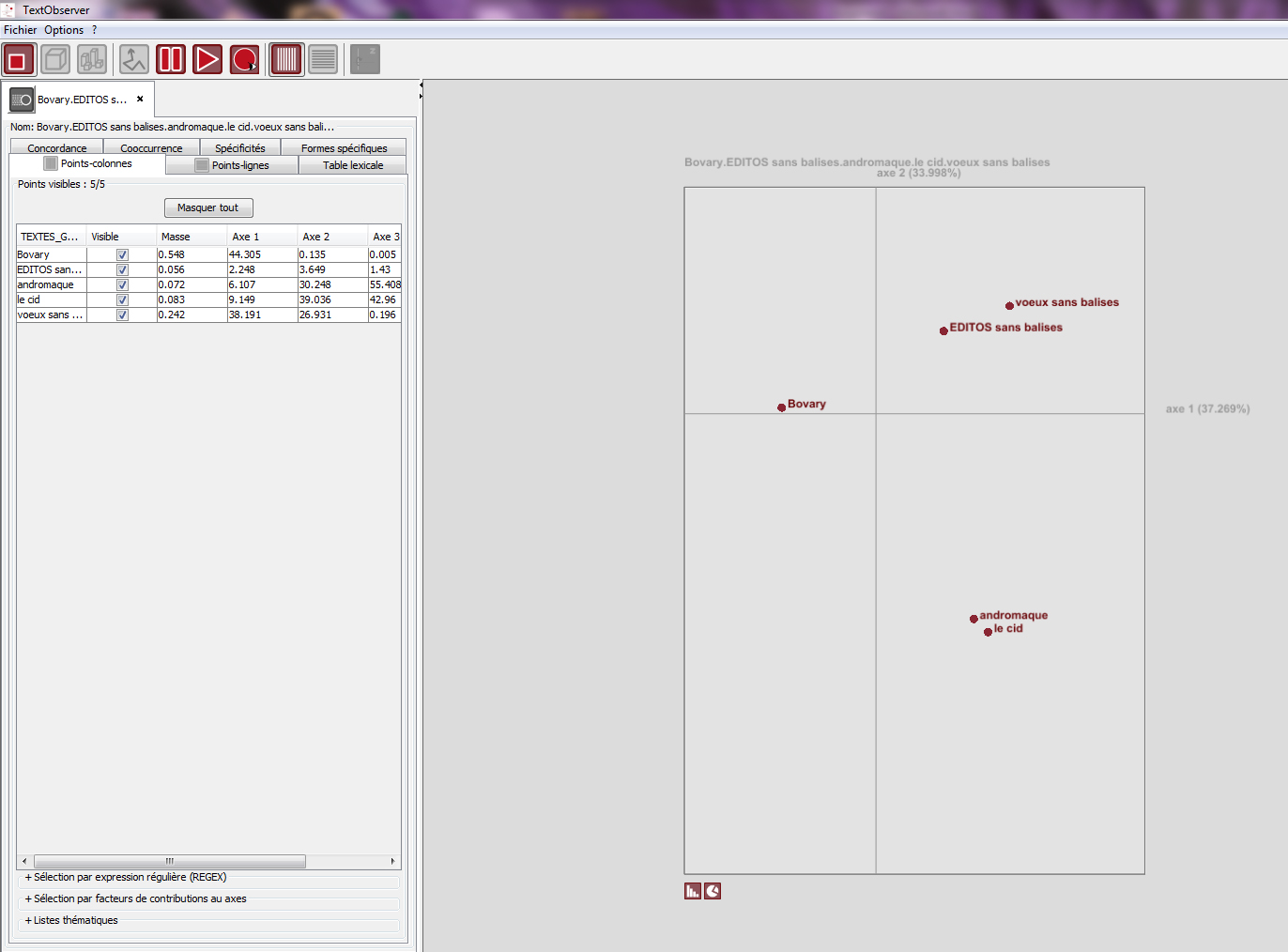
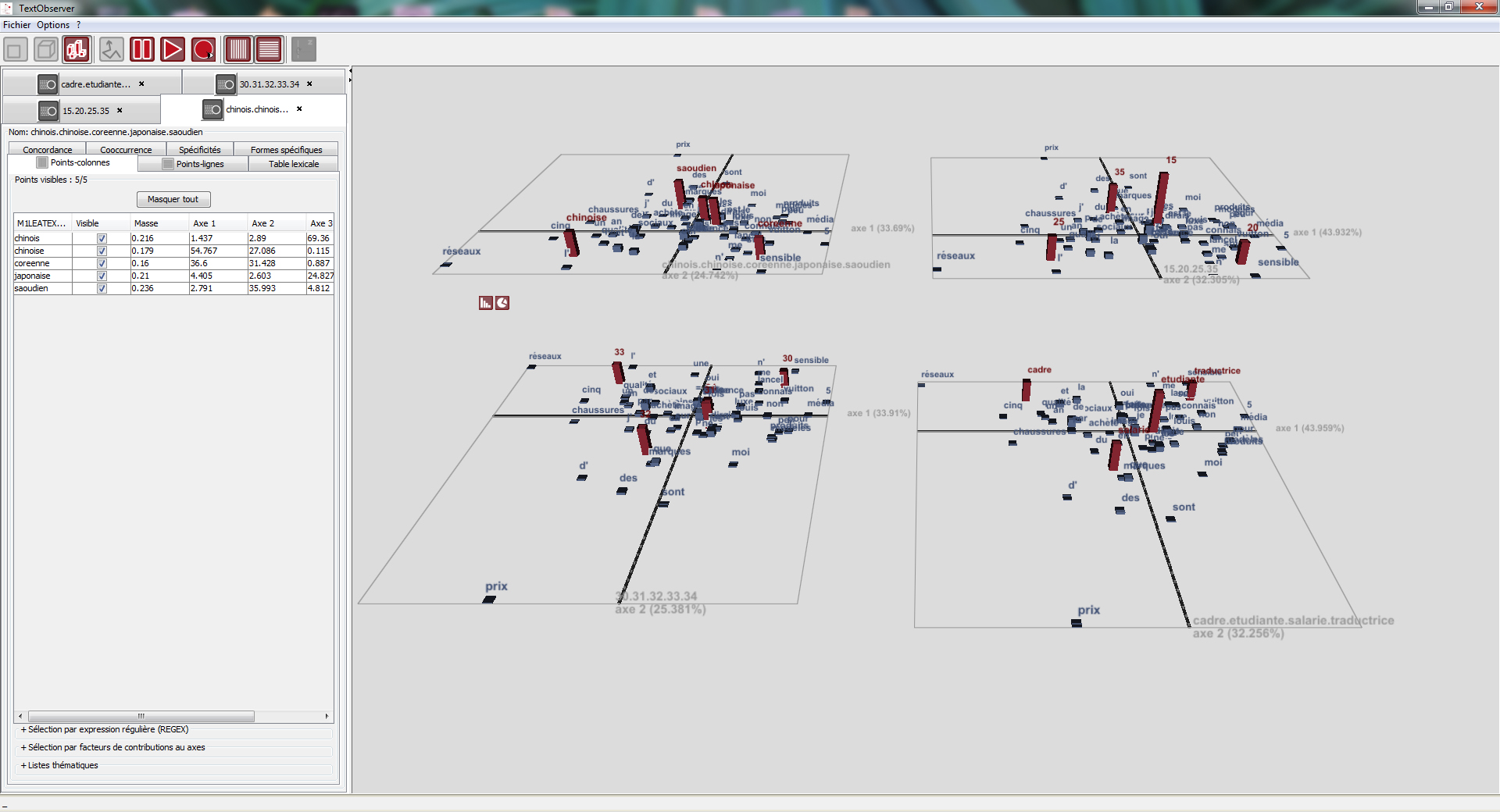
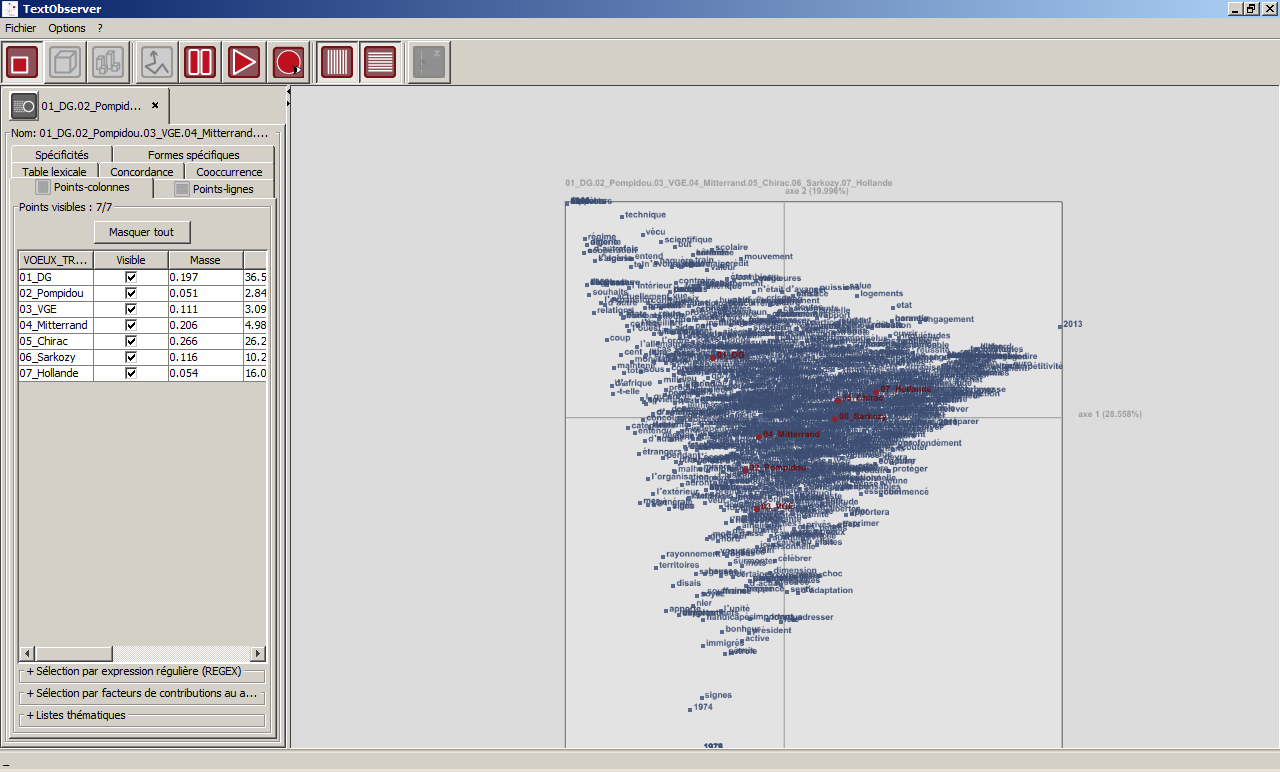
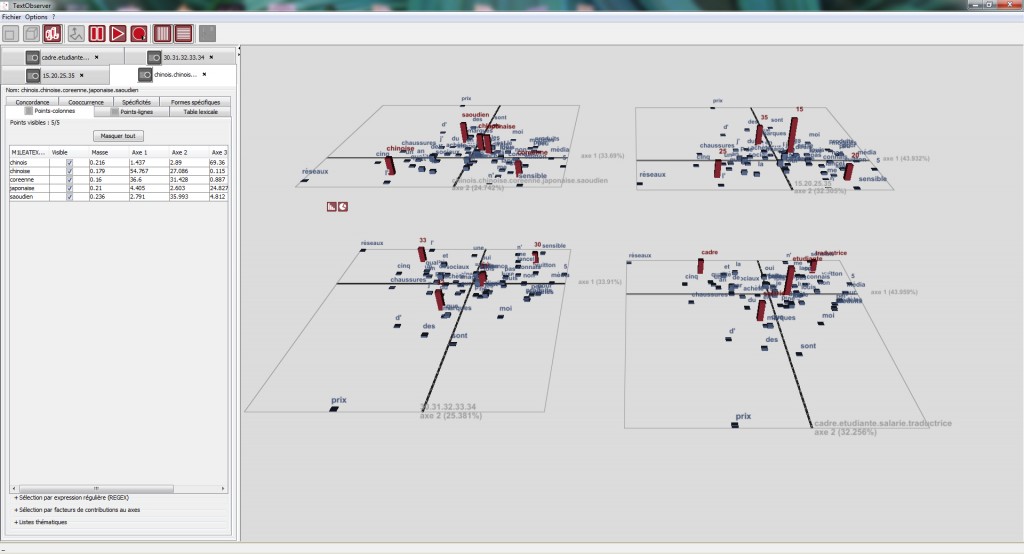
Affichage simultané de 4 partitions d’un même corpus xml
 With TextObserver you can import multi-text files corpus (1 file per partition) or an xml tagged corpus (we have developed TextEncoder software in order to help you to quickly transform Cordial or Treetagger file in xml file).
With TextObserver you can import multi-text files corpus (1 file per partition) or an xml tagged corpus (we have developed TextEncoder software in order to help you to quickly transform Cordial or Treetagger file in xml file).
1. Import xml file
Put the folder containing the xml file in the TextObserver root folder
In Textobserver :
Menu Fichier>Importer>Répertoire de corpus>Format xml…
Select the folder containing the xml files you want to import, and eventually modify the encoding type (*)
2. Creating lexical tables
When the computing is complete, Textobserver open the following window and propose to choose which partition and properties you want in order to create matching lexical tables. The easiest way consists in using default settings. This let Textobserver create all lexical tables matching with xml main partition tags attributes.
In the example, theTextEncoder generated xml file is structure as follows :
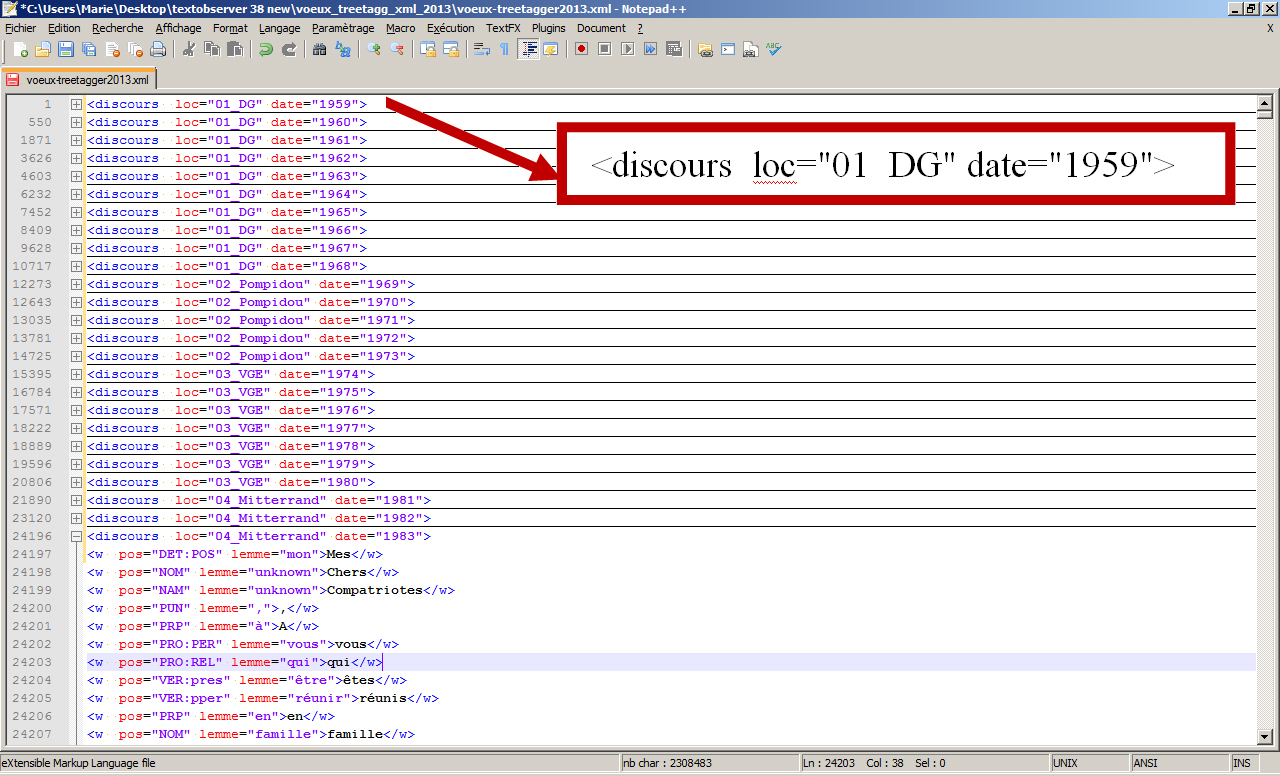
TextObserver repère donc les deux attributs de la balise discours ce qui permet de créer deux tables une pour les discours par « date » l’autre pour les discours par « loc » (locuteurs).
Valider « Créer les tables lexicales » lance leur fabrication.
3. Chargement des tables lexicales
Menu Fichier>Ouvrir>Table(s) lexicale(s) (.tab)…
Choisir la table que vous désirez charger…
* : Le type d’encodage d’un fichier peut facilement être vérifié ou modifié grâce au logiciel gratuit et libre Notepad++ (voir manuel Notepad++ sur Textopol) Il permet également de transformer rapidement un fichier balisé pour Lexico3 en fichier xml (idem)