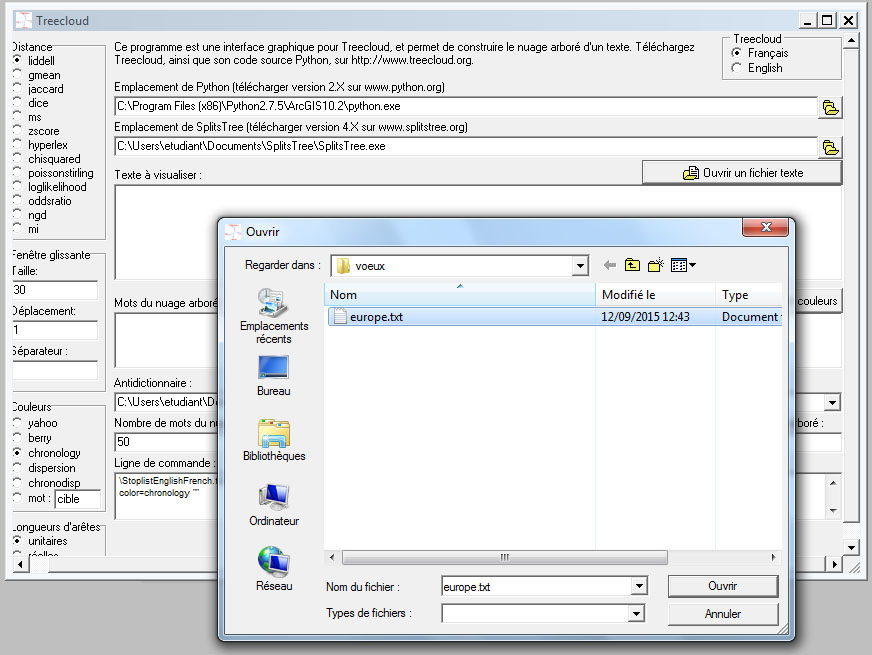
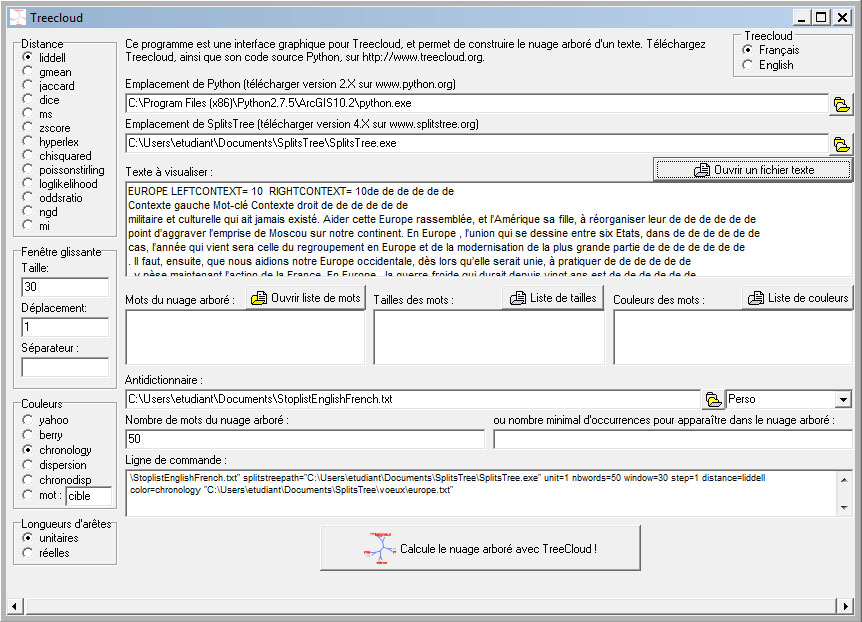
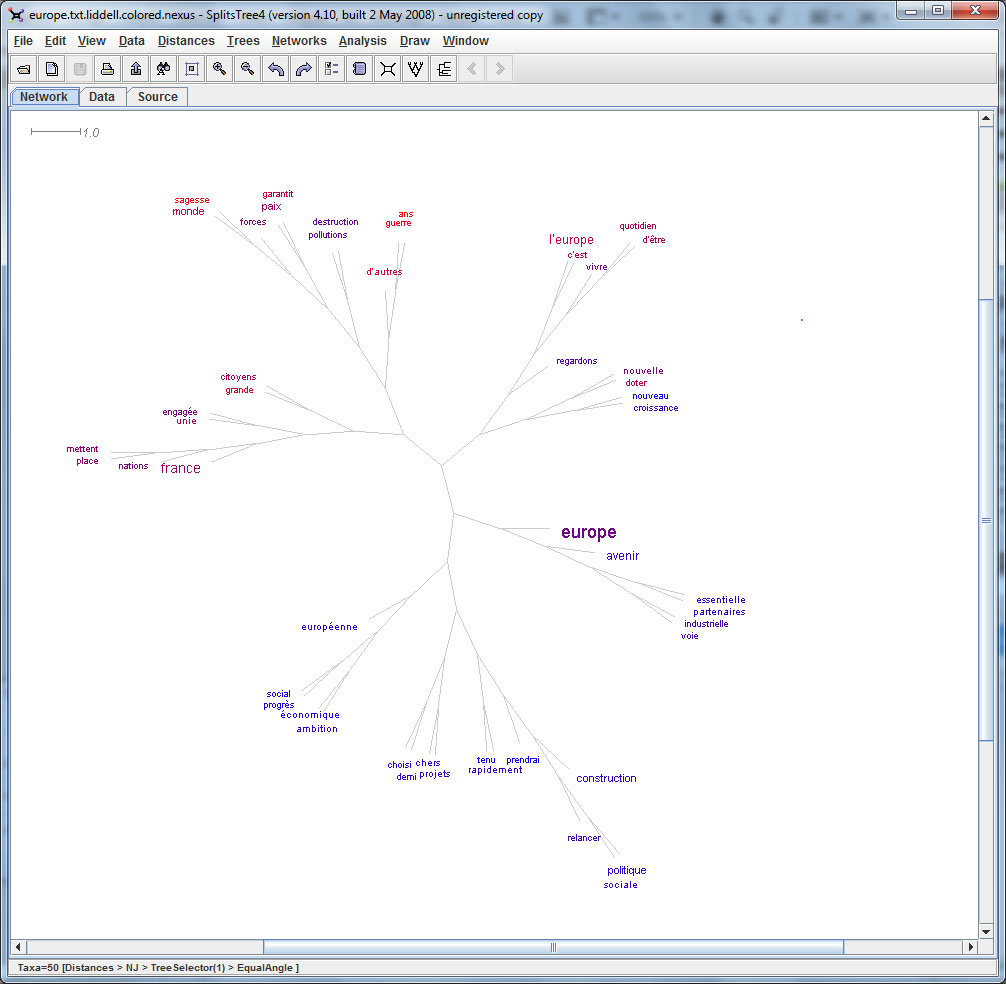
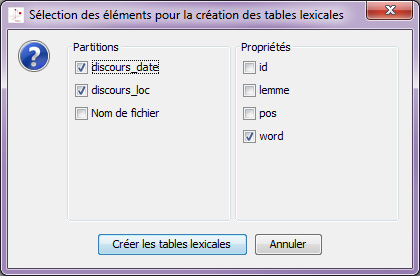
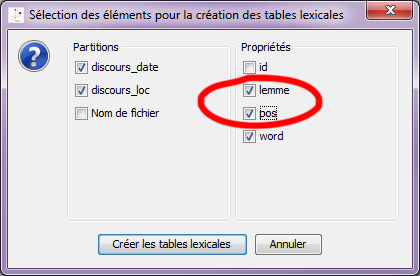
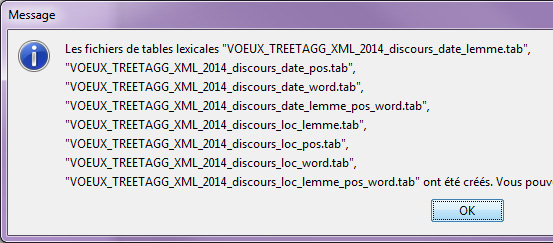
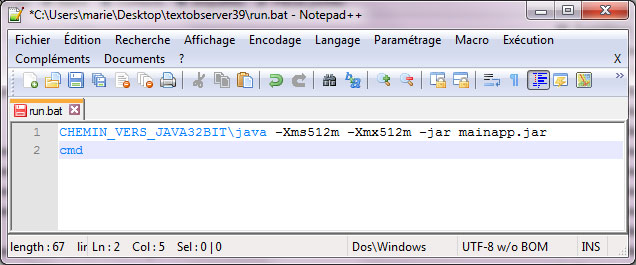
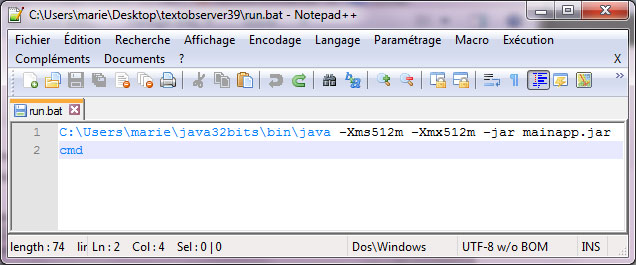
– Sur la forme graphique à partir de la fenêtre concordance –
Quelques fonctionnalités pour bien démarrer
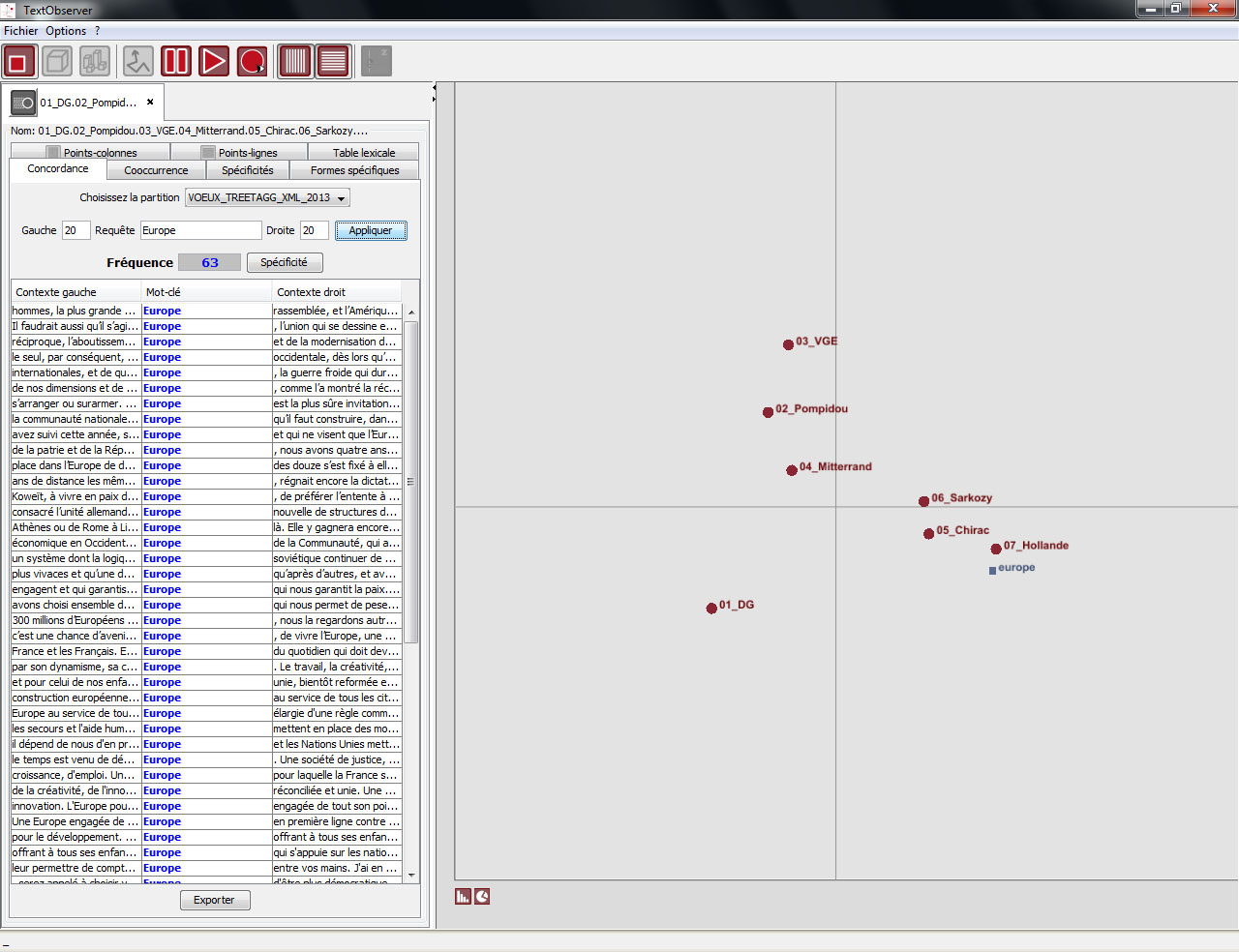
Recherche d’une forme unique (forme graphique). Dans la fenêtre requête de l’onglet concordances saisir la forme recherchée et cliquer sur « appliquer ».
recherche d’une suite mots, portion de phrase, syntagme
Lorsque l’on recherche une suite de mots, une portion de phrase, un syntagme, chaque élément doit être saisi entre guillemets et séparé du suivant par un espace :
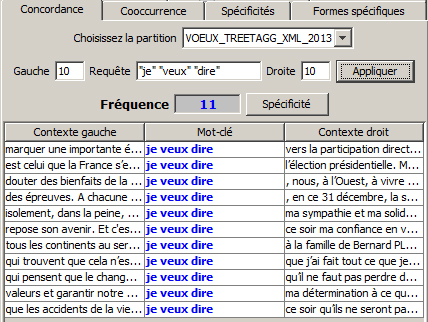
Il est possible d’examiner la répartition du motif recherché entre les différentes parties du corpus en cliquant sur le bouton « spécificité »
Expressions régulières : rechercher la fin d’un mot
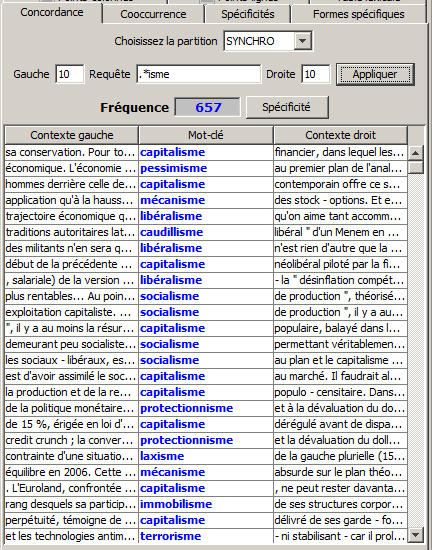
=> tout caractère suivi d’une suite fixe de caractères :
.*isme
>> tutoriel vidéo (constituer une liste à partir des résultats de la requête et modifier l’analyse factorielle des correspondances)
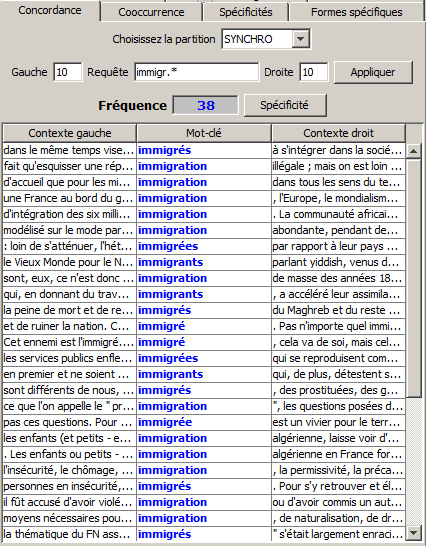
=> mot commençant par une suite fixe de caractères :
immigr.*
=> un mot suivi d’un autre avec un intervalle de x mots entre les deux :
« je » []{1,3} « voudrais »
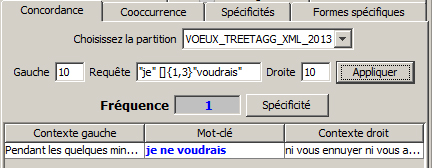
Cet exemple permet de trouver « je » suivi de 1 à 3 mots quelconques suivi de « voudrais ».
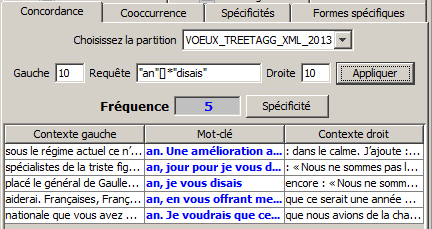
=> recherche de deux mots séparés par un intervalle quelconque
« an »[]* »disais »
« an » suivi de 0 à n mots quelconques suivi de « disais »
=> disjonction :
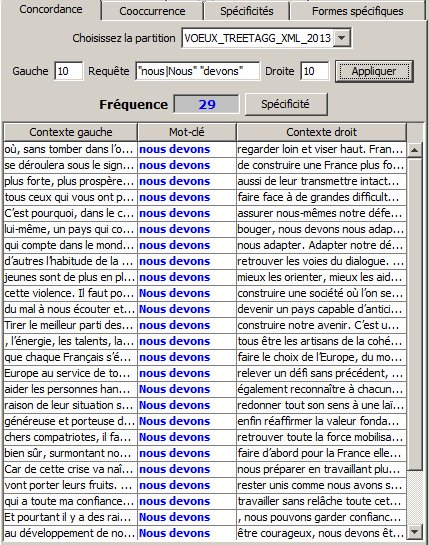
« nous|Nous » « devons »
« nous » OU « Nous » suivi de « devons »
=> exemple combinant la disjonction et des suites de mots :
« nous » « avons » []* « espérer|espoir|confiance »
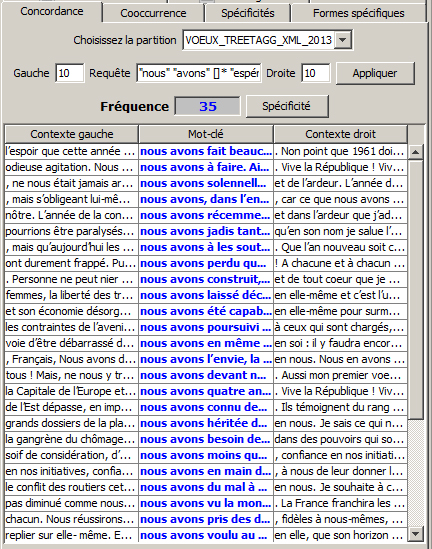
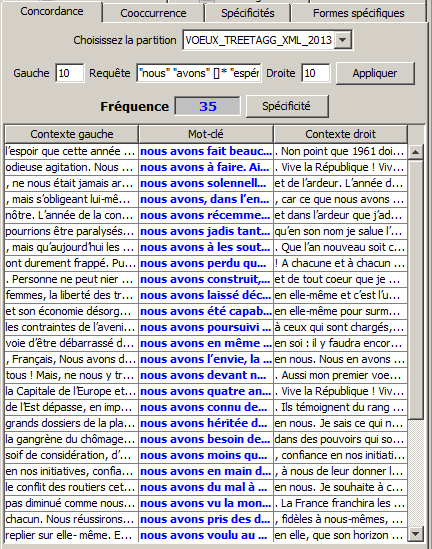
« nous » « avons » []{1,20} « espérer|espoir|confiance »
« nous|Nous » « avons » []{1,20} « espérer|espoir|confiance|raison|raisons »
Le premier exemple permet de trouver « nous avons » suivi de « espérer » ou « espoir » ou « confiance » avec un intervalle libre de mots entre « nous avons » et l’autre mot.
le second permet la même recherche mais définit un intervalle de 1 à 20 mots.
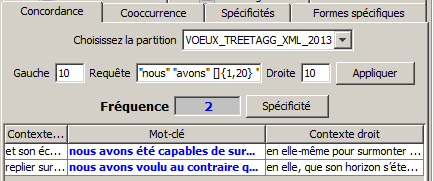
le troisième ajoute permet d’obtenir le résultat qui suit
Syntaxe du motif de recherche
Les caractères:
- . : un point désigne n’importe quel caractère
- ? : le point d’interrogation rend le caractère qui précède optionnel
- tout autre caractère (s’il ne fait pas partie de la syntaxe des expressions) se désigne lui même (a désigne un a, b un b, etc… mais une * à une signification autre que le caractère *)
La recherche ci-dessous combine ainsi un v et un t avec un caractère libre entre les deux
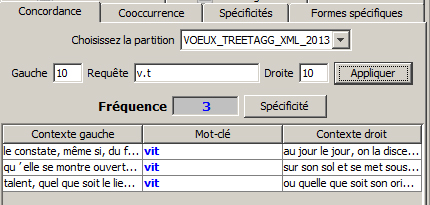
La recherche ci-après rend le s en fin de mot optionnel
Les répétitions
- * : une étoile indique que le caractère présent juste avant se répète n’importe quel nombre de fois (de 0 à l’infini)
- + : un plus indique que le caractère présent juste avant se répète au moins une fois et peut être présent plusieurs fois
Les ensembles
- [] : un ensemble de crochets vide désigne un mot (ensemble de caractère)
- []* : désigne un nombre infini de mots (de 0 à l’infini)
- []{1,4} : désigne un nombre fini de mots (entre 1 et 4 compris)
[à venir : recherche de motifs sur catégories morphosyntaxiques]– On graphical form in concordance tab –
Some features for an easy start
Unique form search (graphical form). In the request’s window of the concordance tab type the word you want to search for then clic on « appliquer ».
Search of a string of words, a sentence’s part, a syntagm
When you search of a string of words, a sentence’s part or a syntagm each word must be put in quote and separated by a space :
Il est possible d'examiner la répartition du motif recherché entre les différentes parties du corpus en cliquant sur le bouton "spécificité"
Expressions régulières : rechercher la fin d'un mot
=> tout caractère suivi d'une suite fixe de caractères :
.*isme
>> tutoriel vidéo (constituer une liste à partir des résultats de la requête et modifier l'analyse factorielle des correspondances)
=> mot commençant par une suite fixe de caractères :
immigr.*
=> un mot suivi d'un autre avec un intervalle de x mots entre les deux :
"je" []{1,3} "voudrais"
Cet exemple permet de trouver "je" suivi de 1 à 3 mots quelconques suivi de "voudrais".
=> recherche de deux mots séparés par un intervalle quelconque
"an"[]*"disais"
"an" suivi de 0 à n mots quelconques suivi de "disais"
=> disjonction :
"nous|Nous" "devons"
"nous" OU "Nous" suivi de "devons"
=> exemple combinant la disjonction et des suites de mots :
"nous" "avons" []* "espérer|espoir|confiance"
"nous" "avons" []{1,20} "espérer|espoir|confiance"
"nous|Nous" "avons" []{1,20} "espérer|espoir|confiance|raison|raisons"
Le premier exemple permet de trouver "nous avons" suivi de "espérer" ou "espoir" ou "confiance" avec un intervalle libre de mots entre "nous avons" et l'autre mot.
le second permet la même recherche mais définit un intervalle de 1 à 20 mots.
le troisième ajoute permet d'obtenir le résultat qui suit
Syntaxe du motif de recherche
Les caractères:
- . : un point désigne n'importe quel caractère
- ? : le point d'interrogation rend le caractère qui précède optionnel
- tout autre caractère (s'il ne fait pas partie de la syntaxe des expressions) se désigne lui même (a désigne un a, b un b, etc... mais une * à une signification autre que le caractère *)
La recherche ci-dessous combine ainsi un v et un t avec un caractère libre entre les deux
La recherche ci-après rend le s en fin de mot optionnel
Les répétitions
- * : une étoile indique que le caractère présent juste avant se répète n'importe quel nombre de fois (de 0 à l'infini)
- + : un plus indique que le caractère présent juste avant se répète au moins une fois et peut être présent plusieurs fois
Les ensembles
- [] : un ensemble de crochets vide désigne un mot (ensemble de caractère)
- []* : désigne un nombre infini de mots (de 0 à l'infini)
- []{1,4} : désigne un nombre fini de mots (entre 1 et 4 compris)
[à venir : recherche de motifs sur catégories morphosyntaxiques]